

































在20世纪中叶以前,药物发现更像是一门“玄学”。科学家们依赖经验和运气,从天然产物中寻找能引起生理反应的物质。
但这种“只知其然,不知其所以然”的表型筛选效率极低。随着受体理论的诞生和分子生物学的兴起,我们才真正开启了靶点导向的理性设计时代。
今天,站在 AI 与大数据的潮头,回看这五次技术迭代的历程,我们能清晰地看到人类是如何将偶然变成必然的。
一、药物筛选技术的五次迭代
药物筛选技术的发展并非线性递增,而是经历了数次范式转移。根据相关文献这一历程可以清晰地划分为五个阶段,每一次迭代都是对前一代局限性的技术突破,也是人类对生命化学本质认知边界的拓展。

第一次迭代:低通量随机筛选
在20世纪中叶以前,药物发现很大程度上是一门依赖经验和运气的“手工艺”。这一阶段的特征是筛选通量极低,且往往缺乏明确的分子靶点。科学家们主要关注天然产物(植物提取物、微生物发酵液等),利用全动物模型(如感染小鼠)或离体组织(如平滑肌条)进行测试。
主要特征与局限:
- 依赖表型:筛选依据是观察到的生理效应(如血压下降、细菌死亡),而非分子层面的结合。这种“表型筛选”虽然能保证化合物在生物体内的有效性,但往往难以阐明其具体作用机理(MoA),导致后续优化困难。
- 通量限制:由于依赖手工操作和生物活体,每天只能筛选几个到几十个化合物。
- 资源限制:化合物来源局限于天然产物和已有的少量合成染料或化学品。
尽管效率低下,这一时期却诞生了抗生素(如青霉素、链霉素)和许多经典药物(如阿司匹林、吗啡),奠定了现代制药工业的基础。
第二次迭代:基于机理的低通量筛选
随着20世纪60-70年代分子生物学和生物化学的兴起,人类开始从分子水平理解疾病机制。受体理论的确立和酶学的发展,使得科学家能够将特定的蛋白质(如酶、受体、离子通道)分离出来作为药物靶点。
范式转变:
- 靶点导向:筛选不再是漫无目的的随机尝试,而是针对特定的生物大分子进行。例如,针对血管紧张素转化酶(ACE)寻找高血压药物。
- 理性设计萌芽:这一阶段开始出现基于底物或已知配体结构的理性设计思想,虽然筛选通量依然受限于手工操作(如放射性配体结合实验),但命中率较随机筛选有了显著提高。
受体理论的确立让“靶点导向”成为了可能,筛选不再是漫无目的的随机尝试 。但在开启大规模筛选之前,一个更为核心的问题摆在了科学家面前:在成千上万个潜在靶点中,究竟哪一个才值得我们投入巨大的资源?
此时,基于大数据的理性设计思想开始超越单纯的分子层面,延伸至战略层面。现代药物研发团队在立项初期,往往会借助一些数据库,如在摩熵医药数据库的全球药物研发数据库里来进行一场“宏观筛选”。
与实验室里的微观筛选不同,这种基于商业与临床数据的宏观筛选,旨在规避拥挤的赛道和高风险靶点。通过分析摩熵数据库中关于特定靶点的全球管线分布、在研药物的临床阶段流转率以及竞品的专利布局,科学家们能够在源头识别出最具潜力的“蓝海”靶点。这意味着,在我们的移液枪吸取第一滴试剂之前,大数据的力量已经帮助我们排除了那些注定无法成药的方向,让后续的高通量筛选(HTS)拥有了更精准的战略锚点。
第三次迭代:基于机理的高通量随机筛选(HTS)
20世纪80年代末至90年代,药物发现进入了工业化时代。自动化液体处理工作站、高密度微孔板(96孔、384孔甚至1536孔板)以及灵敏的检测技术(如荧光、发光)的引入,使得HTS成为可能。
技术爆发:
- 规模爆炸:化合物库的规模从几千种迅速膨胀到成千上万种,大型制药企业的实体库通常包含100万至500万种化合物。
- 工业化流程:筛选变成了一条流水线作业,机器人每天可以测试数万甚至十万个样品。
- 组合化学:为了喂饱HTS这头“巨兽”,组合化学技术应运而生,能够快速合成大量结构多样的化合物库。
面临的挑战:
尽管HTS极大地扩展了搜索范围,但也带来了巨大的成本压力。筛选100万个化合物需要消耗大量的试剂、靶点蛋白和时间。此外,HTS产生的数据虽然庞大,却也混杂着大量的假阳性(False Positives),例如某些化合物可能通过非特异性聚集或干扰检测信号而显色,被称为“频繁击中者”(Frequent Hitters)或“泛测定干扰化合物”(PAINS)。
第四次迭代:虚拟筛选(VS)与高通量筛选(HTS)的串联与整合
为了解决HTS的“高投入、低产出”悖论,计算化学开始走向舞台中央。虚拟筛选(VS)作为一种计算过滤器,被引入到筛选流程的前端。
协同效应:
- 漏斗策略: 科学家不再将所有百万级实体化合物直接送入HTS,而是先利用计算机算法对亿级虚拟库进行初筛,遴选出评分最高的100~10,000种化合物,再进行实体验证。这种“干湿结合”的漏斗模式,显著降低了实验成本,提高了筛选的命中率。
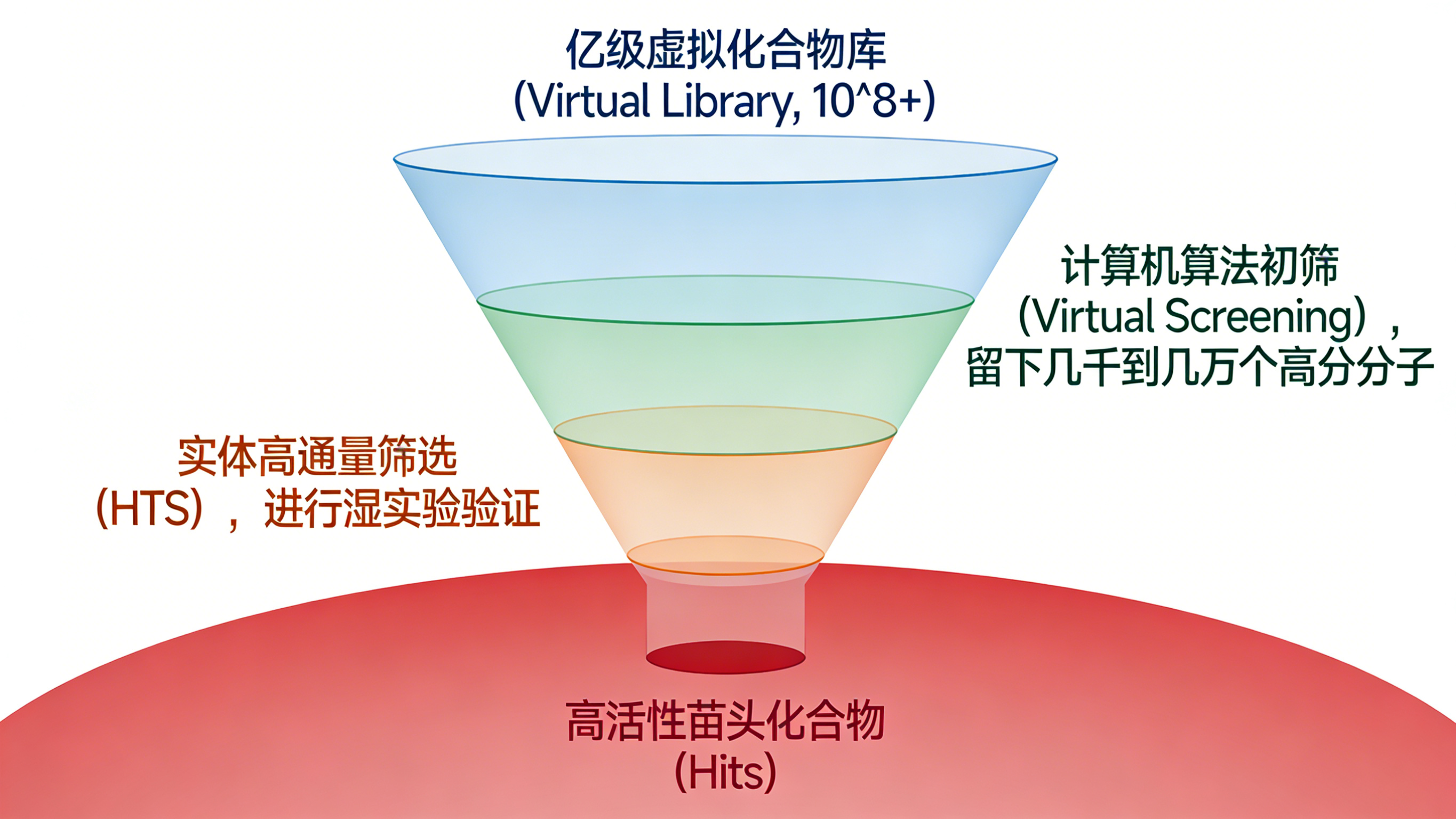
- 互补性: 研究表明,VS和HTS往往能发现不同化学空间的活性分子,二者是互补而非替代关系。例如,在GSK-3β抑制剂的筛选中,VS发现了HTS遗漏的骨架,且命中率(12.9%)远高于HTS(0.55%)。
第五次迭代:基于大数据人工智能建模的药物筛选与预测
这是当前正在发生的革命。随着数字化信息的爆发和深度学习技术的成熟,药物发现进入了大数据与人工智能时代。
核心特征:
- 数据多模态:数据来源不再局限于化学结构和活性数据,还包括科学文献、专利、临床数据、图像(如细胞表型)、组学数据等非结构化数据。
- 从筛选到生成:传统的VS是从现有库中“挑选”分子,而生成式AI能够基于靶点特征“创造”全新的分子结构,并预测其合成路径和多维性质(活性、ADMET、合成可行性)。
- 全流程预测:AI不仅预测分子是否结合,还试图预测分子在细胞内的动态行为、在人体内的代谢过程以及最终的临床疗效。
二、虚拟筛选面临的新挑战与机遇
虚拟筛选领域的大数据问题,并非仅仅是数据量的增加,而是涉及数据的规模、多样性、速度和价值的全方位挑战。
1. 库规模的指数级爆炸
虚拟筛选的核心挑战之一是处理呈指数级增长的化合物库。
- 早期阶段:化合物库主要由几百种基于特定骨架的同系物组成,这仅仅是化学空间的一个微小角落。
- 组合化学时代:随着组合化学技术的发展,通过不同模块的排列组合,库规模迅速扩展到成千上万种。
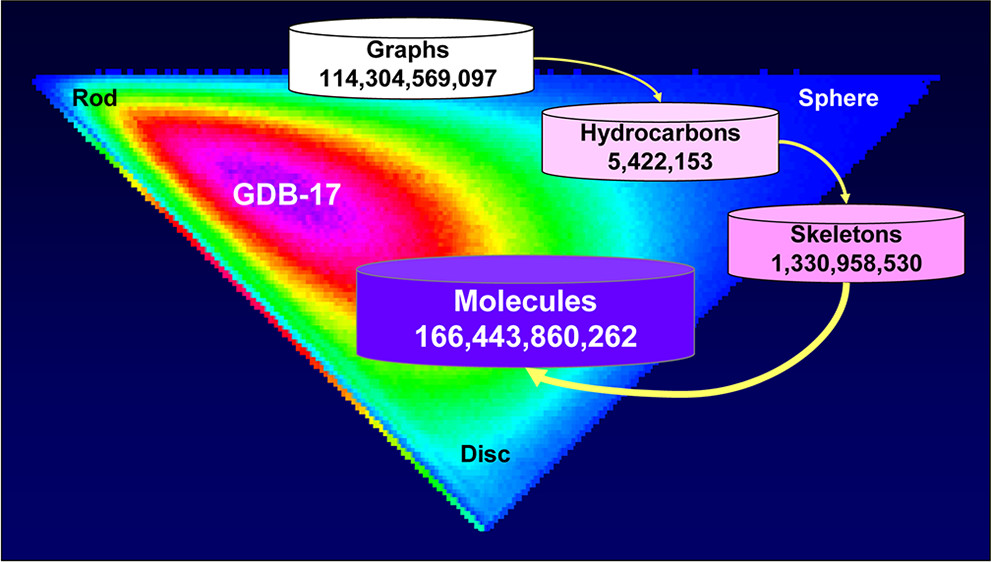
- DNA编码库(DEL)时代:这是近年来最激动人心的技术突破之一。通过将有机小分子与特定的DNA序列标签相连(类似商品的条形码),科学家们可以在一个试管中合成并筛选数十亿甚至上千亿种化合物 。DEL技术使得“百亿级”筛选成为现实,其数据规模之大,使得传统的计算方法面临巨大的算力瓶颈。
此外,理论化学空间的探索更是无穷无尽。GDB-17数据库列出了1664亿个分子,这些分子最多包含17个重原子。如果考虑更大的分子量范围,化学空间的大小可能超过(10^60)^2。面对如此庞大的数据海洋,简单的线性搜索算法已无法应对。如果在100亿个分子的库中,每个分子的对接计算需要1秒钟,那么筛选完整个库需要超过300年。因此,如何从海量数据中快速、精准地识别出有价值的信号,成为了VS技术的核心痛点。
2. 数据的多样性与复杂性
除了规模,数据的类型也在发生质变。
结构化数据:早期VS技术主要依赖结构化数据。
- 基于配体:利用已知活性分子的结构特征(如2D指纹图谱、3D药效团、形状相似性)去寻找类似的分子。这就像是拿着一张嫌疑人的画像去人群中找人,前提是你必须先知道“坏人”长什么样。
- 基于靶标:利用靶点蛋白的三维结构(通常来自X射线晶体衍射或NMR),模拟小分子与蛋白的结合过程(分子对接)。这就像是拿着一把钥匙去试开一把锁,前提是你必须有锁的精确结构。
- 传统机器学习:使用了支持向量机(SVM)、贝叶斯分类器、随机森林等算法,基于分子描述符(如分子量、LogP、氢键供体数等)建立预测模型。
非结构化数据与深度学习:现代VS技术引入了深度学习(Deep Learning, DL)和高性能计算(HPC)。
- 挖掘文献宝藏:深度学习擅长处理自然语言(NLP)和图像。这使得它能够挖掘科学论文、专利文献等非结构化数据中的隐藏模式。例如,通过分析数百万篇文献中的化学反应描述,AI可以学习到哪些反应条件更容易成功,或者哪些结构片段经常出现在特定靶点的抑制剂中。
- 动态模拟与柔性对接:传统的分子对接往往将蛋白视为刚性物体(僵硬的锁)。但在真实生物体内,蛋白是不断运动的,存在“诱导契合”效应。随着HPC算力的提升,基于分子动力学(Molecular Dynamics, MD)的VS技术逐渐成熟。这种方法能够模拟蛋白的柔性变化,捕捉到瞬态的结合口袋,从而更准确地预测结合亲和力,减少漏筛。
3. 数据生成的爆发
相关文献指出,人类数字化信息总量经历了多次爆发,从1986年的0.02 EB暴增到2007年的280 EB,其中69%的信息是在2000-2007年间产生的。在药物发现领域,这种爆发体现为基因组测序数据的激增、高内涵筛选(HCS)产生的海量图像数据、以及DEL库产生的测序读数。这些数据为AI模型的训练提供了丰富的燃料,但也对数据清洗、存储和处理能力提出了极高的要求。
三、虚拟筛选的战术图谱
面对大数据的挑战和单一算法的局限性,科学家们并未坐以待毙,而是开发出了一系列精妙的策略来提高筛选的成功率。这些策略的核心思想不再是寻找一个“完美”的算法,而是通过组合优化、动态反馈和实验整合,来逼近真实的生物活性。
1. 基于共识的虚拟筛选
“三个臭皮匠,顶个诸葛亮。” 这句古老的谚语在药物筛选中同样适用。
虚拟筛选的本质是预测配体与受体的相互作用。然而,没有任何一种单一的算法(无论是AutoDock, Glide, Gold还是Surflex)能够完美地模拟所有类型的相互作用(静电、范德华力、氢键、溶剂效应、熵效应等)。有些算法擅长处理疏水作用,有些则对氢键更敏感。单一模型往往存在偏差。
为了弥补这一缺陷,共识评分策略应运而生。这种方法同时运行多种不同的对接软件或预测模型,然后综合它们的结果。其基本假设是:真正的活性化合物应该在 多种合理的模型中都表现良好,而假阳性通常只在某一种特定的算法偏差下得分较高。
2. 迭代式虚拟筛选
如果说共识筛选是“集思广益”,那么迭代筛选就是“小步快跑,快速纠错”。
传统的线性筛选流程是:计算筛选 → 购买/合成 → 实验测试 → 结束。而迭代筛选将这一过程变为一个闭环。
工作流程:
(1)初始筛选:使用初步模型对库进行筛选,选取少量(如几百个)化合物。
(2)实验反馈:对这批化合物进行实体活性测试。
(3)模型更新:将实验结果(不仅包括活性数据,也包括非活性数据,即“负样本”)立即反馈给计算模型。模型根据这些真实的反馈进行“自适应优化”或重新训练(例如调整打分函数的权重,或训练一个新的机器学习分类器)。
(4)循环迭代:利用更新后的模型进行第二轮筛选,重复上述过程。
迭代虚拟筛选过程
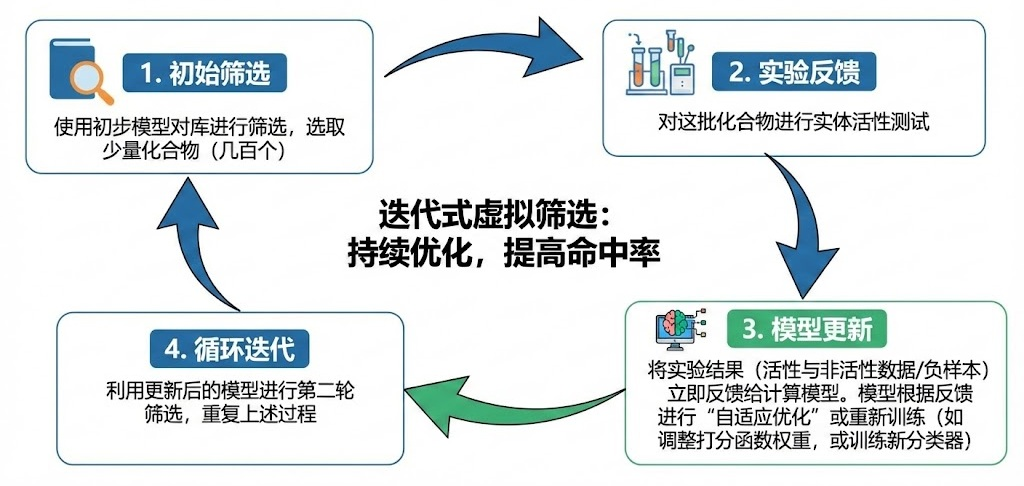
这种方法的核心在于反馈循环。上一轮的“最佳”可能不是全局最优,但它指明了进化的方向。结合遗传算法,这种方法能像生物进化一样,让化合物结构在计算机中不断“变异”和“选择”,最终进化出高活性的苗头化合物。这种方法特别适用于那些初始模型准确度不高,或者靶点信息匮乏的项目。
3. 虚拟筛选与HTS的深度整合:1+1 > 2
在当今的药物发现管线中,VS与HTS不再是竞争关系,而是唇齿相依的战友。将VS整合进HTS流程,已成为必然趋势,二者的结合能够产生显著的协同效应。
经典案例分析:诺华(Novartis)的回顾性分析——剔除假阳性
- 诺华团队对针对26个不同靶点(涵盖激酶、GPCR、PPI等)的约50万个化合物的HTS历史数据进行了深入挖掘。
- 他们利用VS技术对HTS的阳性结果进行了分析。结果发现,大多数VS预测出的苗头化合物(70%~90%)仅针对单一靶标有效,具有很好的特异性。
- 这意味着VS可以有效地帮助科学家识别并剔除那些在所有实验中都显色的“频繁击中者”(Frequent Hitters,通常是干扰实验的假阳性),从而净化筛选结果,聚焦于真正的药物前体。
四、结语
数据规模的指数级爆炸,既是挑战,也是燃料 。深度学习与高性能计算的结合,让我们得以模拟蛋白质的“诱导契合”效应,捕捉那些转瞬即逝的结合口袋 。
未来,随着生成式AI的进一步渗透,药物发现或许将彻底告别“试错”模式,走向真正的“理性设计”。但无论技术如何迭代,核心目标从未改变:用更快的速度、更低的成本,找到那个能拯救生命的分子。
扩展阅读:
2. 成都跻身中国生物药创新一线,2024年6款1类新药获批!
3. 分析条件筛选方法
查数据,找摩熵!想要解锁更多药物研发信息吗?查询摩熵医药(原药融云)数据库(vip.pharnexcloud.com/?zmt-mhwz)掌握药物基本信息、市场竞争格局、销售情况与各维度分析、药企研发进展、临床试验情况、申报审批情况、各国上市情况、最新市场动态、市场规模与前景等,以及帮助企业抉择可否投入时提供数据参考!注册立享15天免费试用!


















 川公网安备51019002008863号
川公网安备51019002008863号 本网站未发布麻醉药品、精神药品、医疗用毒性药品、放射性药品、戒毒药品和医疗机构制剂的产品信息
本网站未发布麻醉药品、精神药品、医疗用毒性药品、放射性药品、戒毒药品和医疗机构制剂的产品信息
收藏
登录后参与评论
暂无评论